

![Kristyn Leffler [Image by creator from ]](/media/images/Kristyn_Leffler.2e16d0ba.fill-500x500.jpg)
There has been an explosion of data science* and machine learning** tech designed for ARM / collections companies and those companies are definitely paying attention. According to a 2020 trends survey from Interactions, over half of ARM participants think of themselves as “innovative” or “disruptive.” What most companies mean by this is that they have invested (or would like to invest) in the tools that define "innovative" and "disruptive" in 2021: data science, machine learning, and AI.
But here's the thing many of these organizations may not understand: no company can realize the promise in those tools unless they have a solid foundation in basic data hygiene
The Path to Innovative Starts with Basic
What do I mean? Let’s rewind *an undisclosed number of years* to your high school psychology or undergraduate Psych 101 class. Remember Maslow’s Hierarchy of Needs? Maslow's Hierarchy arranges needs in a pyramid that goes from basic at the bottom to self-actualized at the top. The main point here is that no one can expect to fulfill a top need - like realizing one's full creative potential - if they're lacking in basic needs from that bottom tier - like food, water and shelter.
You can’t have a real-time, cloud-based machine learning algorithm that predicts and delivers “right time, right message, right channel,” if you don’t first meet your basic needs of gathering, storing and cleaning your data
Just as you can’t achieve “self-actualization” in your personal life if your basic needs aren’t met, you can’t realistically aspire to a the data science equivalent of “self-actualization” - a real-time, cloud-based machine learning algorithm that predicts and delivers the “right time, right message, right channel” to optimize your collections netback - if you don’t first meet your basic needs of gathering, storing and cleaning your data. Monica Rogati makes this point more generally with her “Data Science Hierarchy of Needs,” a concept that heavily influenced this piece.
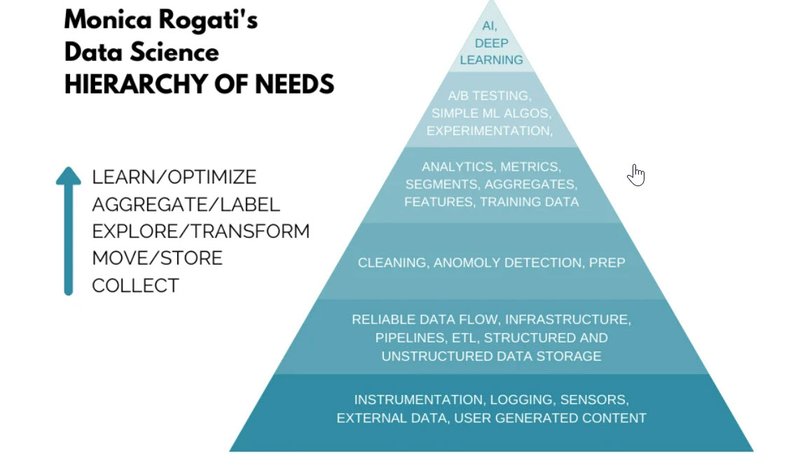 Data science is a discipline and a critical foundation for the successful deployment of machine learning and AI. (You can read more about this idea in a recent Harvard Business Review article and in a recent post on Medium.) Before ARM companies can get to that sexy AI ideal, they need to understand what these basic data needs and practices are, how far they are from meeting this critical standard, and what they need to do to get there.
Data science is a discipline and a critical foundation for the successful deployment of machine learning and AI. (You can read more about this idea in a recent Harvard Business Review article and in a recent post on Medium.) Before ARM companies can get to that sexy AI ideal, they need to understand what these basic data needs and practices are, how far they are from meeting this critical standard, and what they need to do to get there.
[article_ad]
Where Most ARM Companies Are Now
Fortunately, the increased focus on compliance over the past decade in the ARM industry has forced players to improve documentation, logging, and storage of every interaction we have with our customers. As a result, most of us can feel comfortable moving up from the “collect” level into the “move/store” level. If you have multiple clients and/or lenders demanding increased transparency across your portfolio, you have probably also begun to invest in this storage and communication level. You have reporting in place to produce your monthly forecasts and meet client demands. You know which accounts are being called, emailed, texted, or lettered, how often, and exactly how much you can spend on these channels to turn a profit this month, this quarter, and maybe this year. You might even have controls in place to ensure this data is consistent and trustworthy over time. A “call” today is logged and stored the same as a “call” yesterday or a “call” a year ago.
This brings us to the precipice of the “explore/transform” level, and where I estimate the majority of ARM participants fall today. With that background and assumption, here are the 4 mistakes you’re probably making on your data science journey...and how to fix them.
Mistake #1: The Wrong Tool for the Job
The foundation for your data science endeavors must itself sit on a bedrock of well-defined use cases and a shared strategic vision for the direction of your organization. If your data science team (in-house or external consulting resources) doesn’t understand the vision, how an algorithm will be used to drive business strategy, and what the definition of success looks like, the effort is bound to fail. Worse yet, if you don’t understand the pain points in your organization, and where machine learning can add tangible value, then you’re embarking on a confusing, frustrating, and probably expensive journey. Return first to the simplest questions. What problems do you need to solve for your organization today, next quarter and a year from now? What problems can you solve for your client partners that they don’t know they need solved? Do you know whether and where you have the data you need to answer these questions? Assuming yes, are any of those problems really best served by a real-time, repeatable algorithm? Or are those problems best served with ad-hoc questions and analysis by a handful of analysts armed with basic SQL and Business Intelligence tools? (Power BI, Tableau) If your most pressing questions are in the vein of
- Which clients are your most profitable?
- How can you win more business from these clients?
- How do you win client scorecards?
- How do your RPC rates vary by: portfolio, phone provider, time of day?
- What device are customers using to access your website?
- What payment method results in the highest net collections?
- What payment plan offer generates the best payer rate?
- Which skip vendor returns the most actionable data?
- What is the most-asked question by your customers on the phone?
then you’re best served by investing first in data governance, controls, and an analyst workforce, not a machine learning model. Work towards making these analyses repeatable and distributable by building a foundation of reporting that answers these common questions. This will free your analysts to tackle the next set of problems and allow your strategic leaders to start making data-driven decisions. Only then can you progress to higher levels of data science.
Mistake #2: Tech Myopia
The fact is, no “hard” problem we in collections face today hasn’t already been solved by one of the tech giants. Google, Amazon, Facebook, and Apple have already figured out authentication, data privacy and security, combining siloed cross-channel data, channel optimization, frictionless payments, and all while delivering excellent customer experience. Their influence is felt now in the explosion of ARM tech we now see. We don’t need to re-invent these wheels for the collections space, we just need to re-frame our pain points more generally and approach them from the perspective that they’ve already been solved. The answer exists - it may just be in a different industry vertical than ours. Too often we close ranks and seek “previous experience in financial services” or “x+ years revenue cycle management expertise” in our job postings. Instead hire an analyst who isn’t afraid to look to other industries for inspiration and mentorship.
Mistake #3: Garbage In, Garbage Out
The “garbage in, garbage out” adage has never been truer than in applications of data science and machine learning. While it may be tempting to attempt to leap from where you are in the lower levels of your data science pyramid up to the pinnacle of machine learning, it’s simply not sustainable. You (or your newly hired analyst team) must put the work in to clean, prep, segment, and aggregate your data appropriately before attempting to deploy machine learning. Through this process of understanding your data you’ll likely uncover pockets of value just waiting to be discovered, as well as opportunities for cleansing and curating. I can almost guarantee you have data duplication and inconsistency across the various processes you have that touch phone numbers, for example.
The reality is that almost every machine learning solution, from pure coding to the “drag-and-drop” model building interfaces that many vendors sell, requires clean, curated data that fit together sensibly.
You may have heard terms like “data lake” and “unstructured data” and dreamed of dumping your existing disparate data sources into a vendor’s black box from which emerged a beautiful and accurate “ML” algorithm, but that simply isn't the reality. The reality is that almost every machine learning solution, from pure coding to the “drag-and-drop” model building interfaces that many vendors sell, requires clean, curated data that fit together sensibly. Additionally, unless you opt for a truly black box solution, the output of machine learning solutions should almost always be evaluated by individuals with the proper subject matter expertise. A reliable machine learning solution is the product of having a team of analysts that can both build and understand your business’ datasets, not a way to bypass those steps altogether. Finally, a machine learning solution in production cannot exist without reliable data pipelines to feed the algorithm - even the most sophisticated model cannot add business value without a reliable source of data. A “hacked together” solution may work, but is doomed to eventual failure. Invest in the foundational levels of the pyramid - your analysts and your data professionals (DBAs, data engineers) - before you look to machine learning.
This is the computer science portion of data science and you cannot skip this step, nor should you want to.
Mistake #4: "Drive-Through" Analysis
Perhaps the most insidious mistake on this list is when companies convince themselves that these problems can be magically solved by an elite group of specialists within your organization (or by external consultants). In fact, even the most eminently qualified statistics PhDs will still have to spend considerable time and effort understanding basic aspects of the data, including where it lives, how it was generated, and how it fits together.
The job of making sense of the data cannot fall only to a “drive through” statistician or to a team of isolated analysts. You must drive a collaborative culture between your subject matter experts (at a minimum collections representatives, client relations, database administrators) and those tasked with building a model. Building models in a vacuum will cause dissatisfaction among all parties. The data science team will make incorrect assumptions about how the data was created and be forced to do a significant amount of re-work while the subject matter experts will be forced to use a model in which they don’t feel invested. Collaboration is king
Building a Data-First Culture
How can you avoid these mistakes? Surprise! The key to a sustainable approach to your data science journey is building a data-first culture and analyst workforce with domain expertise within your organization. I cannot stress enough the value that an analyst (or 5!) can bring to an organization. Hire a smart, curious analyst with a thick skin to poke at your data. Give them a pile of information, access to the subject matter/domain experts to help them make sense of what the data means and how it was created, permission to ask the “stupid” questions, time and space to make mistakes, and watch the magic happen. Even better, hire an analyst with no prior collections experience. Give your analysts a seed question, then let them form and test their hypotheses using outside ideas. Best yet, ask your analysts to validate or disprove your long held heuristic measures. Have them pit competing ideas against each other in A/B experiment tests, find the winner, then find the next problem. You may be surprised. Ultimately, your goal should be to empower your analysts to work together with your strategy and subject matter experts to build an understanding of what is happening in the organization, formulate and test new solutions and hypotheses to known problems, and fold the winning strategies into your business processes. Now all of a sudden, you’ve reached the “learn/optimize” level 5 of the pyramid.
How to Get to the Top of the Pyramid? Start at the Bottom.
After deploying your new army of analysts to find hidden waste, uncover pockets of value, and use these insights to hone your collections strategy through a robust experiment framework you should have some resources left over to pursue the pinnacle of the pyramid - unsupervised deep learning - if you choose. You may also decide that your organization isn’t yet ready or willing to move to this level whether for data quality, compliance risk, or engineering overhead/cost reasons. Returning to Maslow and Rogati, that top-of-the-pyramid data ideal isn’t a required step. It is aspirational. But if you want to get there, you have to solve your analyst problem first.
I hope you find this article helps you “Think Differently” about your organization’s needs and approach to integrating data science.
*I use the term “data science” to mean uncovering the value to your organization in your pile of data. Typically, this field sits at the intersection of business domain knowledge, computer science (coding), and statistics. Data science only truly exists when all three work together.
**I use the term “machine learning” to mean using computer power to identify patterns in data that are too complicated to be uncovered by human eyes. The output of machine learning is often a “model” or “algorithm” - an equation or system of equations that allow you to classify or predict an outcome based on the information you have available. There are a few methods to accomplish machine learning, but that isn’t prerequisite knowledge for this article.
Bonus Reading:
"4 Ways to Democratize Data Science in Your Organization," from the Harvard Business Review
"Data Scientists and ML Engineers Are Luxury Employees," from Towards Data Science
---------------
Want more collections strategy insight like this delivered right to your inbox? Sign up for the iA Strategy & Tech Newsletter.

iA Innovation Council is a collaborative working group of product, tech, strategy, and operations thought leaders at the forefront of analytics, communications, payments, and compliance technology. Group members meet in person (and lately, virtually) several times each year to engage in substantive dialogue and whiteboard sessions with the creative thinkers behind the latest innovations for the industry, the regulators who audit and establish guardrails for new technology, and educators, entrepreneurs and innovators from outside the industry who inspire different thinking.
2021 members include:
|
2nd Order Solutions AllianceOne Receivables Management Alorica Arvest Bank Attunely BBVA BC Services Beyond Investments Capital Collection Management Cedar Financial Citizens Bank Collection Bureau of America Crown Asset Management CSS Impact Dial Connection |
ERC Exeter Finance Firstsource Advantage Healthcare Revenue Recovery Group Hunter Warfield Imagined.Cloud InDebted Katabat Livevox MRS BPO NCB Management Services Neustar Numeracle Ontario Systems Phillips & Cohen
|
PRA Group Professional Finance Company Radius Global Solutions Resurgent Revenue Group RevSpring Spring Oaks Capital State Collection Service TCN The CMI Group TransUnion Tratta TrueAccord Unifund CCR
|
![the word regulation in a stylized dictionary [Image by creator from ]](/media/images/Credit_Report_Disputes.max-80x80.png)
![Cover image for New Agent Onboarding Manuals resource [Image by creator from insideARM]](/media/images/New_Agent_Onboarding_Manuals.max-80x80_3iYA1XV.png)

![[Image by creator from ]](/media/images/New_site_WPWebinar_covers_800_x_800_px.max-80x80.png)
![[Image by creator from ]](/media/images/Finvi_Tech_Trends_Whitepaper.max-80x80.png)
![[Image by creator from ]](/media/images/Collections_Staffing_Full_Cover_Thumbnail.max-80x80.jpg)
![Report cover reads One Conversation Multiple Channels AI-powered Multichannel Outreach from Skit.ai [Image by creator from ]](/media/images/Skit.ai_Landing_Page__Whitepaper_.max-80x80.png)
![Report cover reads Bad Debt Rising New ebook Finvi [Image by creator from ]](/media/images/Finvi_Bad_Debt_Rising_WP.max-80x80.png)
![Report cover reads Seizing the Opportunity in Uncertain Times: The Third-Party Collections Industry in 2023 by TransUnion, prepared by datos insights [Image by creator from ]](/media/images/TU_Survey_Report_12-23_Cover.max-80x80.png)
![Webinar graphic reads RA Compliance Corner - Managing the Mental Strain of Compliance 12-4-24 2pm ET [Image by creator from ]](/media/images/12.4.24_RA_Webinar_Landing_Page.max-80x80.png)